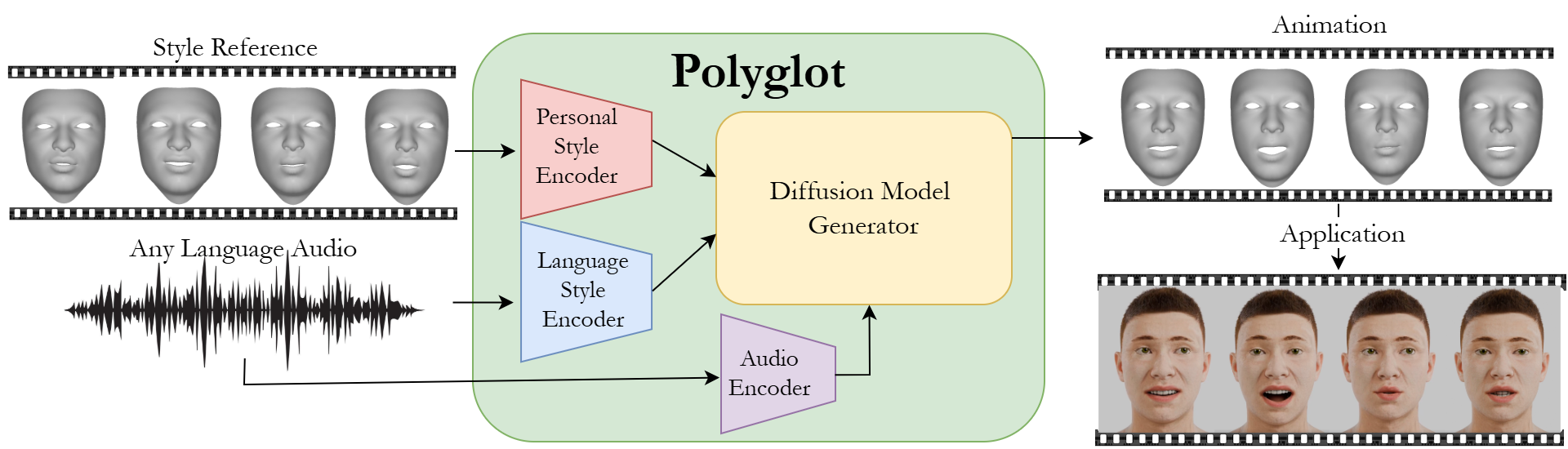
We present Polyglot, a unified diffusion-based framework for multilingual speech-driven facial animation that preserves both language-specific characteristics and personal speaking style. By jointly conditioning on transcript-derived language embeddings and speaker-style embeddings extracted from reference facial motion, Polyglot generates expressive, temporally coherent facial animation across multiple languages and speakers.
Speech-Driven Facial Animation (SDFA) has garnered significant attention due to its applications in movies, video games, virtual reality, and digital humans. However, most existing methods are trained on single-language data, limiting their ability to generalize to multilingual real-world scenarios. Human speech is deeply shaped by language, affecting not only phonetics but also rhythm, intonation, and facial articulation. In addition, people speaking the same language can exhibit markedly different personal speaking styles.
In this work, we introduce Polyglot, a single unified diffusion-based architecture for personalized multilingual SDFA. Our method uses transcript embeddings to encode language-aware information and speaker-style embeddings, extracted from reference facial motion, to capture person-specific habits. Polyglot does not rely on predefined language labels or speaker-specific IDs, enabling stronger generalization across languages and speakers. By jointly conditioning on language and style, Polyglot generates expressive facial animations that better reflect both the linguistic structure of the speech and the identity of the speaker.
Polyglot combines four key components: a multilingual speech encoder, an automatic speech recognition (ASR) module, a text encoder, and a style encoder. Given an input audio sequence, mHuBERT extracts temporal speech features, Whisper produces the corresponding transcript, and a text encoder (CLIP) generates language-aware embeddings. In parallel, a style embedding is computed from a reference motion sequence using a dedicated style encoder, capturing speaker-specific dynamics.
These signals are jointly fused within a Transformer-based diffusion decoder, which is conditioned on identity, language, style, and the diffusion timestep. The decoder progressively denoises a noisy motion sequence to produce the final facial animation, enabling temporally coherent and expressive results.
The style encoder is trained separately using an autoencoding objective, where a decoder reconstructs motion sequences from the extracted style embedding. Once trained, the style encoder is frozen and used during Polyglot training to ensure consistent preservation of personal speaking style.
We introduce PolySet, a multilingual dataset derived from the MultiTalk corpus. PolySet contains paired audio and 3DMM expression parameter sequences spanning 20 languages. We refine the source data by filtering noisy samples based on perceptual audio quality and reconstruction quality, resulting in a balanced, high-quality benchmark for multilingual speech-driven facial animation.
After filtering, PolySet contains 10,000 sentences sampled at 25 fps, with each language contributing 450 training samples and 50 validation and test samples, for a total of roughly 16 hours of clean data.